Most AI model releases in 2026 follow a familiar pattern: larger model, better benchmarks, new pricing tier. Grok 4.20 does something different. It does not just add more parameters — it adds more perspectives. Grok 4.20 Beta is xAI's latest AI model, publicly launched on February 17, 2026. The version number, 4.20, is classic Elon Musk — a deliberate internet culture wink. But the engineering underneath it is dead serious.
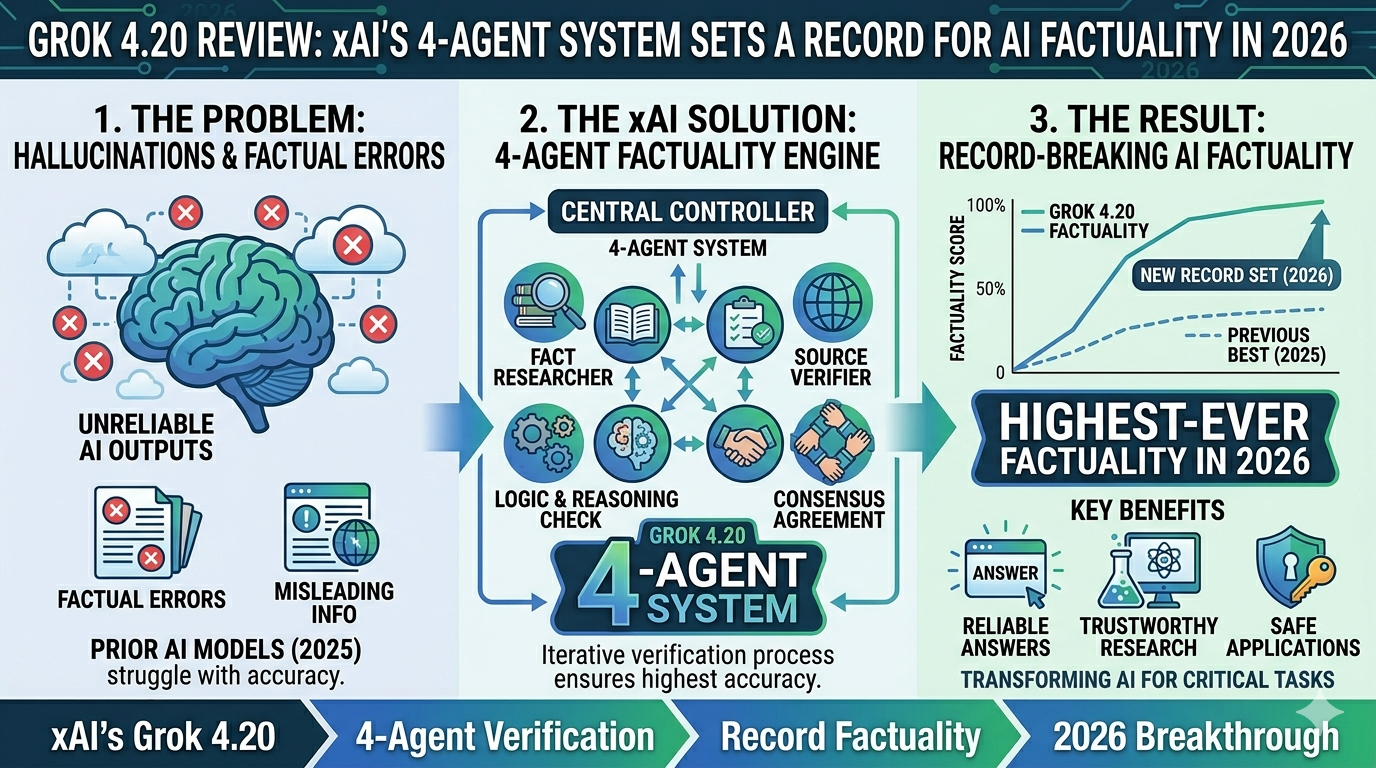
The defining feature of Grok 4.20 is not a number. It is an architecture: four specialized AI agents that think in parallel, debate each other's outputs, and synthesize a consensus answer before responding. This is not a user-orchestrated framework like AutoGen. It is baked directly into inference, which means every complex query automatically benefits from internal peer review without any developer configuration required.
The 4-Agent Architecture: How It Actually Works
When you submit a complex query to Grok 4.20, you are not talking to a single model. You are triggering a coordinated multi-agent workflow that resembles a small expert team reviewing your question before responding.
| Agent | Role | Primary Function |
|---|---|---|
| Grok (Captain) | Coordinator | Decomposes the task, formulates strategy, resolves conflicts, synthesizes the final answer |
| Harper | Research and Fact-Checking | Searches real-time X data, verifies factual claims, flags inaccuracies |
| Benjamin | Logic and Mathematics | Handles reasoning chains, mathematical calculations, and code verification |
| Lucas | Contrarian Analysis | Introduces creative angles, spots biases in other agents' outputs, improves balance |
The internal debate phase is where the hallucination reduction happens. Cross-agent verification drops the hallucination rate from approximately 12% down to roughly 4.2% — a 65% improvement over single-model baselines. For tougher tasks, a Heavy mode scales this to 16 agents. The marginal cost of running four parallel agents is reported to be 1.5 to 2.5 times a single pass rather than four times, because the agents share KV cache and the debate rounds are short and RL-optimized.
The X Data Advantage: Real-Time Factuality
Every other major AI model — GPT-5.4, Gemini 3.1, Claude Opus 4.6 — relies on training data with a cutoff date. For questions about events from last week, last month, or this morning, they either guess, refuse to answer, or use an external web search tool with unpredictable quality.
Grok has something different: native access to the X platform's live data stream. Harper, the fact-checking agent, uses this access in real time during inference. This means Grok 4.20 can answer questions about news events from the last 30 days with a factual grounding that no other model can match natively. Grok integrates real-time X data for current events and sentiment analysis — ChatGPT relies on static training data. For use cases involving financial news monitoring, competitive intelligence, breaking news analysis, and social media sentiment, this is a genuine structural advantage.
On factual reliability, Grok 4.20 is currently best in class. The 78% AA Omniscience non-hallucination rate is a record. This is the benchmark that matters most for real-world production use — a model that's slightly less intelligent but significantly less likely to confidently fabricate an answer is often more useful.
Artificial Analysis Model Review, March 2026Performance and Pricing: Where It Stands
xAI launched Grok 4.20 in three API variants with pricing up to 60% cheaper than Grok 3, setting a record non-hallucination rate of 78% on the Artificial Analysis Omniscience test. The model ranks 8th on the Intelligence Index with a score of 48 — below leaders Gemini 3.1 Pro and GPT-5.4 at 57. This is an honest trade-off: Grok 4.20 is optimizing for reliability over raw benchmark dominance. For production applications where a confident wrong answer is worse than a correct one, that trade-off often makes more sense than chasing leaderboard rankings.



