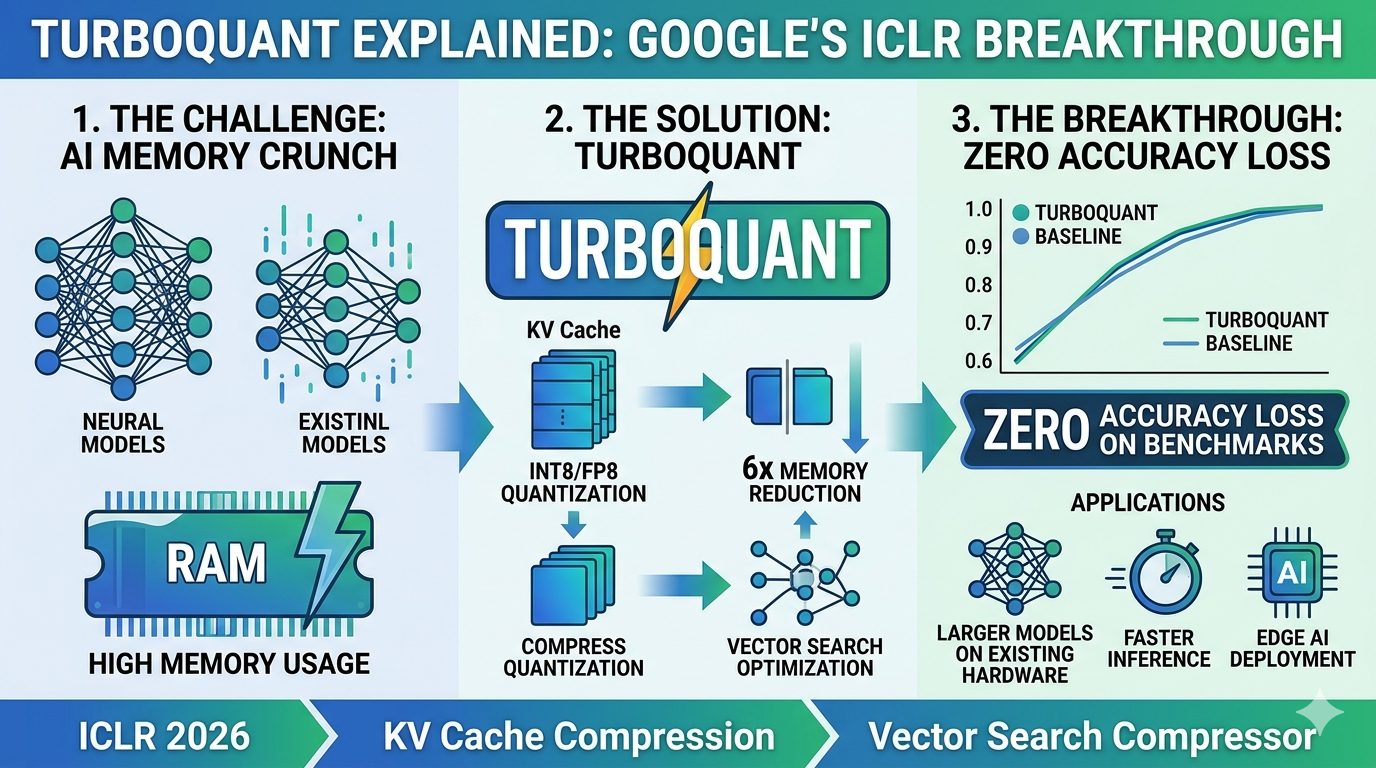
If you have ever run a large language model on your own hardware and watched your GPU memory disappear as the context window grows, TurboQuant was built for exactly that problem. And if you have never had that experience, here is why it matters: the memory bottleneck is not a developer inconvenience — it is one of the most expensive constraints in all of modern AI, costing the industry billions of dollars in infrastructure every year.
On March 24, 2026, Google Research published what many are calling a landmark paper in efficient inference. Google Research published TurboQuant, a training-free compression algorithm that quantizes LLM KV caches down to 3 bits without any loss in model accuracy. In benchmarks on Nvidia H100 GPUs, 4-bit TurboQuant delivered up to an eight-times performance increase in computing attention logits compared to unquantized 32-bit keys, while reducing KV cache memory by at least six times. Within 48 hours of publication, memory chip stocks fell, Cloudflare's CEO called it "Google's DeepSeek moment," and independent developers had already ported implementations to PyTorch and Apple's MLX framework.
What Is the KV Cache and Why Does It Cause Problems?
To understand why TurboQuant matters, you need to understand what a KV cache is. When a transformer-based language model generates text, it computes key and value vectors for every token in the conversation and stores them so it does not have to recompute from scratch at every step. Think of it as the model's short-term memory for your session.
The problem is that this memory grows linearly with the length of the conversation. Running a 70-billion-parameter model for 512 concurrent users can burn through 512 GB of cache memory alone, nearly four times what the model weights themselves consume. For companies serving millions of users simultaneously, this is not a theoretical concern — it is the single largest driver of inference infrastructure costs.
How TurboQuant Works: Two Stages of Compression
TurboQuant is a compression method that achieves a high reduction in model size with zero accuracy loss, making it ideal for supporting both key-value (KV) cache compression and vector search. It accomplishes this via two key steps: High-quality compression (the PolarQuant method): TurboQuant starts by randomly rotating the data vectors. This rotation spreads the statistical energy uniformly across all coordinates, making the data dramatically easier to compress without distortion. After rotation, each coordinate follows a predictable distribution, allowing the use of mathematically optimal quantization buckets computed in advance using the Lloyd-Max algorithm.
The second stage applies the Quantized Johnson-Lindenstrauss algorithm using just 1 bit of residual compression capacity. The QJL stage acts as a mathematical error-checker that eliminates bias, leading to a more accurate attention score. The result is compression that approaches the theoretical information-theoretic optimum — meaning there is very little room for future algorithms to do significantly better at this precision level.
What It Means for Context Windows and AI Deployment
TurboQuant allows systems to handle 4 to 8 times longer context windows or significantly larger batch sizes on the same hardware without running out of memory. In other words, it is less about reducing total memory needs and more about improving efficiency. For a developer currently hitting out-of-memory errors at 16K context on a 16GB GPU, TurboQuant can push that boundary to 64K to 128K context on the same machine.
The implications for enterprise AI deployment are significant. Compression scales with context length. The benefit is proportional to how much KV cache you have. At 512 tokens the savings are modest. At 4K tokens you start saving over 1GB. At 8K or more tokens the savings reach 2GB or more on a single model — and that is when it starts changing what you can actually run on your hardware.
TurboQuant matters less because it saves a bit more memory, and more because it marks where KV-cache compression starts to hit a real boundary — the information-theoretic limit of what compression can achieve without harming model quality.
TurboQuant.net Independent Analysis, April 2026The Bigger Picture: Efficiency-First AI
TurboQuant arrives at a moment when the AI industry is being forced to confront the economics of inference. Training a model is a one-time cost, however enormous. Running it, serving millions of queries per day with acceptable latency and accuracy, is the recurring expense that determines whether AI products are financially viable at scale. The key-value cache is central to this calculation: it is the bottleneck that limits how many concurrent users a single GPU can serve and how long a context window a model can practically support.
The trend TurboQuant represents is the industry's shift from parameter scaling — adding more weights to a model to make it smarter — toward efficiency-first engineering, where the same capabilities are delivered with dramatically less compute and memory. This shift benefits every organization running AI at scale, from hyperscalers to startups to individual developers.



